项目概述
项目背景
本项目使用孪生神经网络(Siamese Network)对 Fashion MNIST 数据集进行相似度学习。孪生网络通过学习样本间的距离度量,能够有效地识别两个图像是否属于同一类别。
与传统分类方法不同,相似度学习能够处理未见过的类别,并且在样本数量有限的情况下仍能取得良好的性能。
模型架构

孪生网络架构图:两个共享权重的特征提取器和基于欧氏距离的相似度计算
Fashion MNIST 数据集
Fashion MNIST 包含 10 类服装图像,每类 7,000 张训练图像和 1,000 张测试图像,总共 70,000 张 28x28 像素的灰度图像。

T-shirt/top

Trouser

Pullover

Dress

Coat

Sandal

Shirt

Sneaker

Bag

Ankle boot
训练过程
训练历史
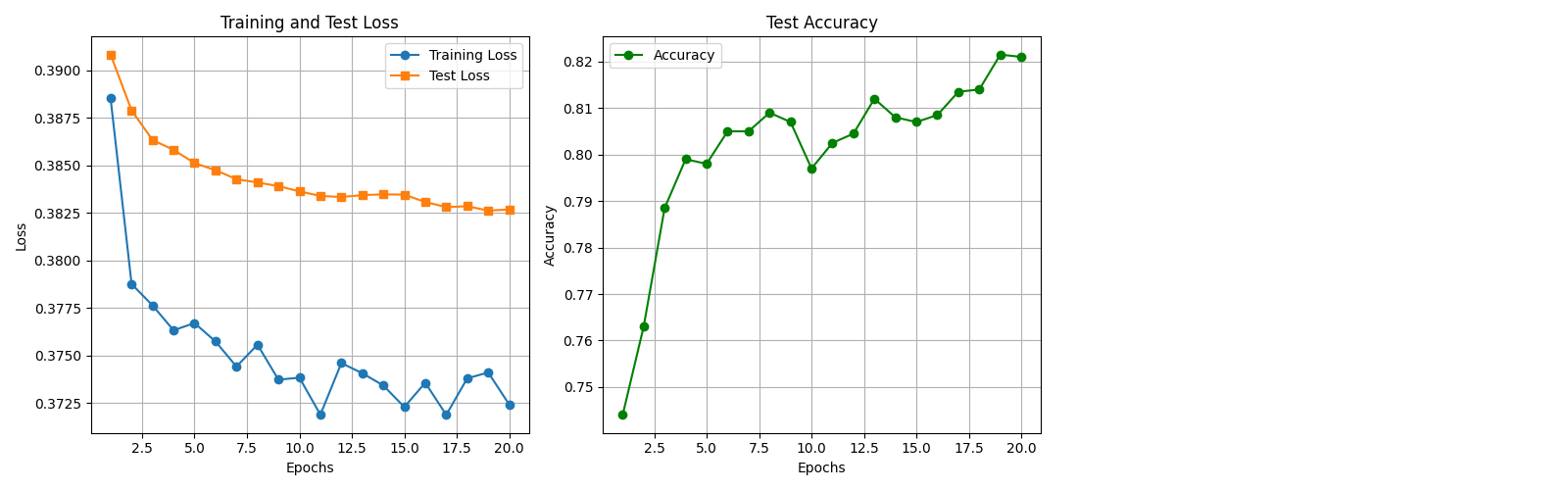
上图展示了模型训练过程中损失和准确率的变化。左图展示训练集和测试集的损失曲线,右图展示测试集的准确率。
训练参数
| 参数 | 值 |
|---|---|
| 训练轮数 | 20 |
| 批次大小 | 128 |
| 学习率 | 0.001 |
| 对比损失边界值 | 1.0 |
| 优化器 | Adam |
| 特征维度 | 64 |
| 训练对数量 | 10,000 |
模型性能
性能指标
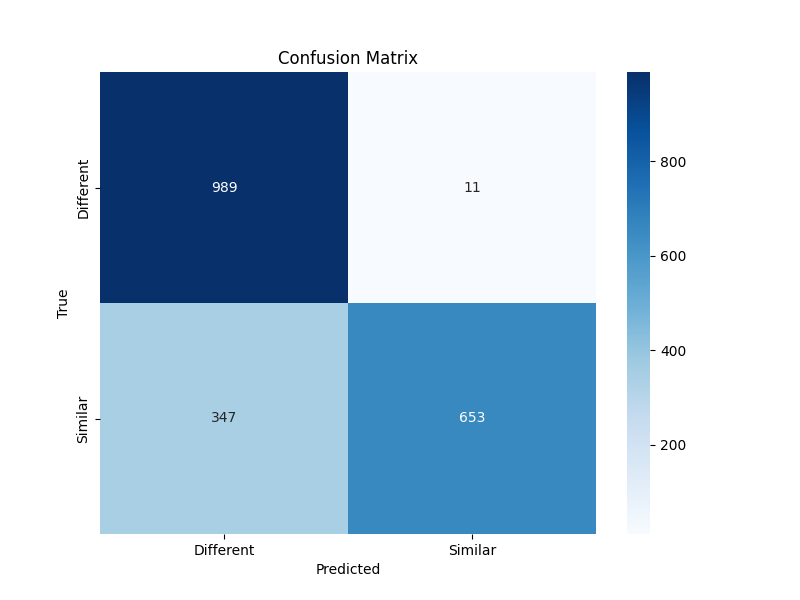
混淆矩阵
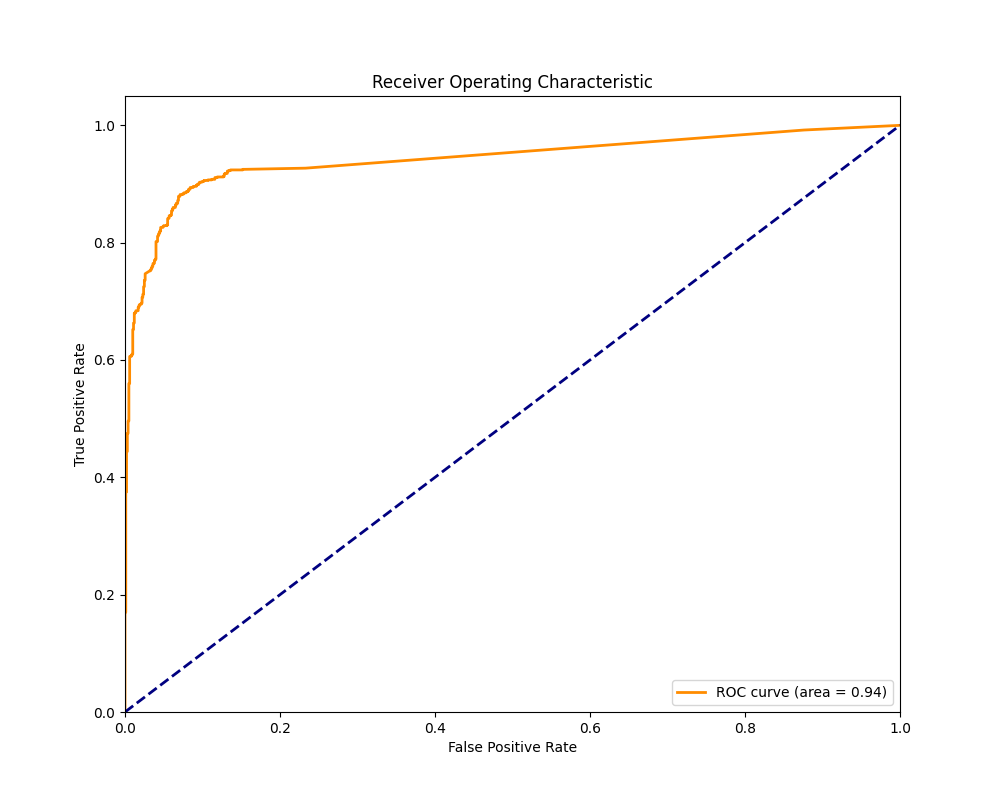
ROC 曲线
相似度分布
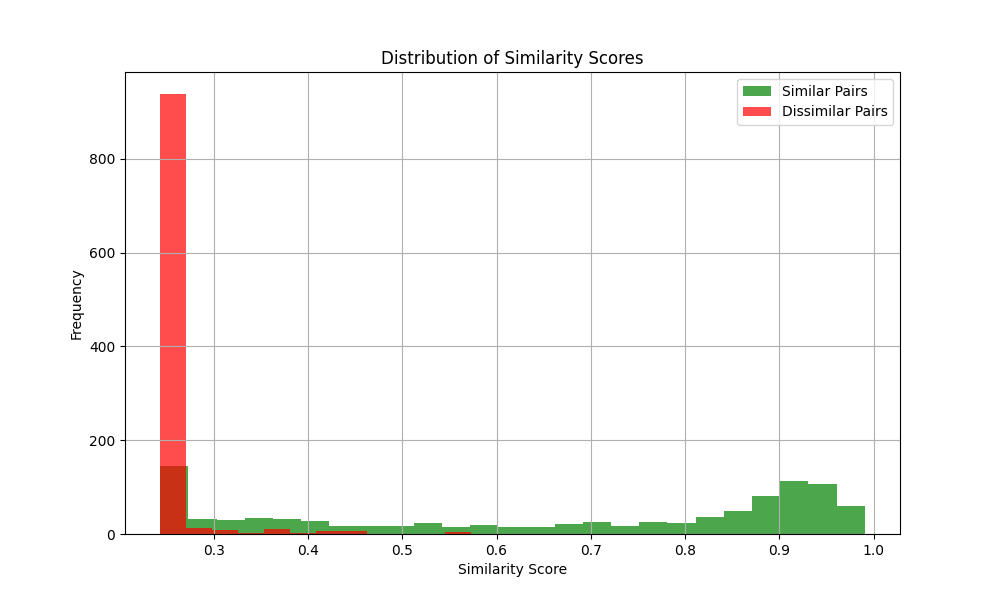
此图显示相似对和不相似对的相似度分数分布。理想情况下,这两种分布应该明显分离。
特征可视化
t-SNE 特征空间可视化
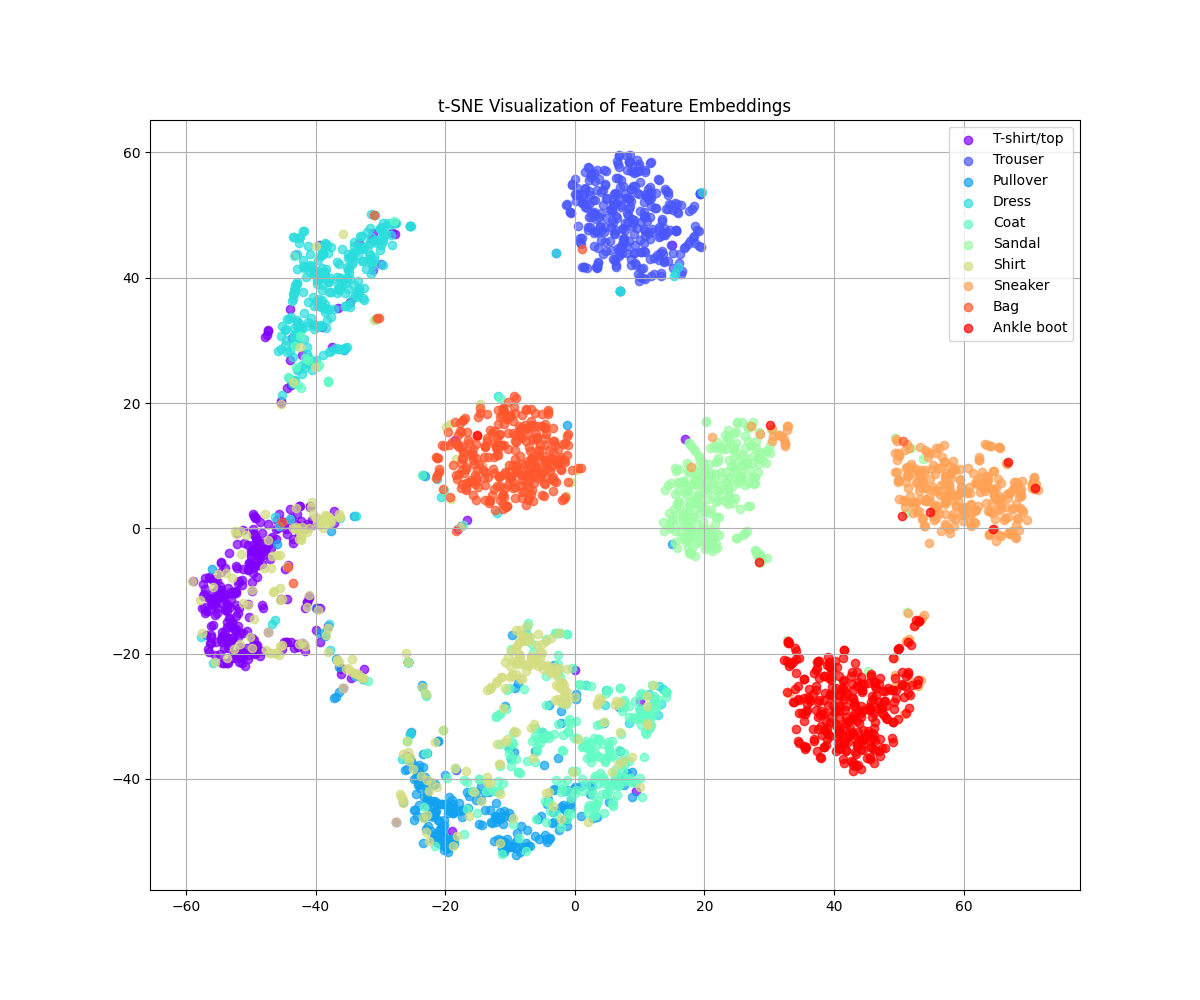
t-SNE 将高维特征空间投影到二维平面,使我们能够可视化样本的分布情况。相同颜色的点代表同一类别,点之间的距离表示样本相似度。
困难样本分析
误分类的样本对

上图展示了模型难以正确分类的样本对。左侧为假阳性(实际不相似但被预测为相似),右侧为假阴性(实际相似但被预测为不相似)。
误分类原因分析
- 假阳性原因:某些不同类别的服装(如衬衫和 T 恤)具有相似的视觉特征和轮廓,导致模型将它们视为相似。
- 假阴性原因:同类服装有时会有很大的视觉差异(如不同款式的靴子),使模型误判为不同类别。
类别相似度分析
类别间相似度热力图
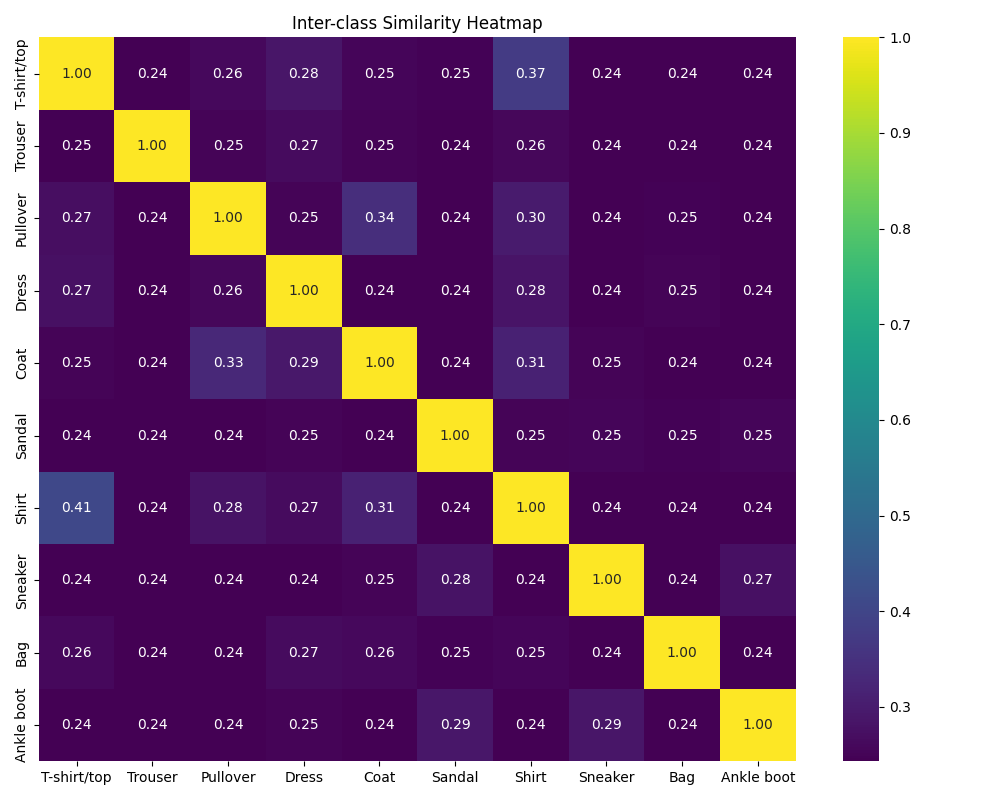
此热力图显示不同服装类别之间的平均相似度。颜色越亮表示两个类别越相似。
主要发现
- 衬衫 (Shirt) 和 T 恤 (T-shirt/top) 之间的相似度较高,这解释了为什么这两类之间容易发生误分类。
- 运动鞋 (Sneaker) 和靴子 (Ankle boot) 有一定的相似性,但与其他类别的相似度很低。
- 上衣类(如 Pullover, Coat, Shirt)之间的相似度普遍较高,表明它们共享一些共同的特征。
- 包包 (Bag) 与其他所有类别的相似度都较低,这表明它具有独特的特征。